Documenting events: do you really need to?

Demystifying complex systems
When working with complex software systems, it quickly becomes apparent that we need to organize and coordinate efforts to avoid implementation chaos. Therefore, the basis of any good software system design is the use of abstractions, e.g. interfaces and APIs.
Still, when our system grows, the amount of created abstractions dramatically increases. Because of this, the meaning and usage of those abstractions can be lost in translation. This becomes even worse when systems are publicly exposed. In the synchronous world, many approaches have been introduced to mitigate this problem. A well-known example is the OpenAPI spec for REST interfaces.
At Cymo, our focus lies on Event-Driven Architectures (EDA). More specifically, our goal is to understand the business logic and processes of our customers and create a matching design. This results in a Business Event-Driven Architecture (BEDA). As the name suggests, the building blocks for such a design are business events.
From experience, we have seen systems with a significant amount of different business events. Teams quickly lose track of what already exists, the scope and meaning of certain events, what can be reused and adapted versus when to create new events, what represents a data product, what can be used for reporting ...
That is why this blog will introduce certain concepts to demystify a complex BEDA landscape and practices that we consider crucial to ensure future growth and success of our projects. Keep in mind that the recommendations we make in this blog are based on our experience and are not a complete analysis of all possible solutions currently available.
The truth about documentation
First things first, I want to make sure we are on the same page when it comes to documentation.
When talking about documentation, reactions mostly involve rethinking one's life choices. I am taking the liberty to assume we have all experienced the need to document the systems we work on. It is a task we greedily start with as we are convinced it will aid in the understanding of the system. However, when this documentation has its own lifecycle, it inevitably becomes an outdated artifact of a past where someone still had the spirit to keep documenting every change and agreement about said system. The documentation then becomes counterproductive as it is no longer an exact representation of reality.
That is what we call static documentation. It has the tendency to be written once at the start of a project, potentially having updates in the first phases of the project, and eventually goes stale and becomes outdated as future changes to the system will no longer be reflected in it. Prominent examples of this kind of documentation are the more than 50-page requirement documents. They have their purpose, and can be important to the initial design of a software system, but they should be archived once their goal has been achieved and they should not be used as “active” documentation.
An alternative is to have dynamic documentation, where the lifecycle of the documentation is tied to that of the system being built. This kind of documentation is usually more concise and precise. It ‘lives’ close to the implementation artifacts of the system and might even be generated automatically in a CI/CD pipeline. The ownership of the documentation is tied to the ownership of the system. The documentation becomes reliable and usable and possibly even interactive.
When we at Cymo talk about documenting your business events, we talk about dynamic documentation that clarifies the meaning and the use of the events. We talk about documentation that can be shared and interacted with by different stakeholders in order to understand the capabilities of the system and to find what is at their disposal (or lacking) to create business value.
A written agreement works better in the long run
When starting with an EDA design, we advocate to start early and potentially fail fast. In other words, we do not want to wait until the whole architecture and all possible business events for all possible use-cases have been defined and agreed upon. The process of defining the big picture, e.g. using event storming sessions, and drilling down to specific business use-cases is a continuous evolving process where changes to your business flows are reflected in your business events.
The keyword here is change. A system that does not change is a system that is dying. Therefore, we need to be prepared and understand the impact certain changes will have on the system and on its users. Because we apply an event-driven design, we rely on events serving as our interfaces for communication and integration between different components of our system or even between systems altogether. We abstract away from the internal implementations and the only changes we concern ourselves with are changes in the structure of these events.
In order to make change as flexible as possible, we could opt for the path of least resistance and use a free format for our events or a format without a formalized structure (e.g. plain JSON). Initially, your developers will be very happy as it is easy to get your events implemented and deployed into production. However, this has multiple pitfalls. First of all, how do I know, as a consumer, I will get the data in a format that I understand and expect? Secondly, what happens when there are changes to the events in case business requirements have changed? Can the producer of the events simply change the format and hope consumers will be able to cope?
This quickly leads to problems in integration. Moreover, the advantage of flexibility becomes useless. That is why we need better agreements or contracts that define exactly what an event looks like and what the possibilities are for future changes. A solution is to apply a schema to our events. There are several protocols, like JSON Schema, Protobuf or Avro, that allow us to define such schemas. In this blog, we focus on Avro. For more explanations about the differences between the different protocols, a good starting point is this blog post: Schema Registry in Kafka: Avro, JSON and Protobuf.
Avro to the rescue and its relation to documentation
Avro is a data serialization framework that uses a schema to correctly serialize and deserialize data into and from binary format. An Avro schema is defined using the widely known JSON syntax which lowers the threshold for adoption. A key aspect of Avro and its use of schema, is the support for changes over time. That allows us to use Avro schemas as contracts in our system and to have a precise understanding of which changes are allowed within the contract.
We will not take a deep dive into Avro and its potential for change. To get more information on this topic, see: Practical Schema Evolution with Avro, or Schema Evolution and Compatibility. What we are interested in, for this blog, is how Avro can help us document our events and understand our Event–Driven Architecture. Take the following example of an Avro schema representing a “product created” business event:
product_created.avsc
{
"type": "record",
"name": "product_created",
"namespace": "com.acme.erp.product",
"doc": "A record representing the creation of a product in our erp system",
"tags": [
"Gold", "PII",
"COMPATIBILITY_TYPE=FULL_TRANSITIVE"
],
"fields": [
{
"name": "id",
"type": "long",
"doc": "The unique identifier of the product"
},
{
"name": "name",
"type": "string",
"doc": "The full name of the product"
}
]
}What we see in this example, is that adding “doc” fields to your schema, either on record level or on field level, allows you to add information about the event and its specific fields. Using additional fields like “tags”, makes it possible to also add extra information to further detail the context of the event. In this example, we can observe that the event has a priority PII and is labeled as ‘Gold’, as it contains crucial information within the ERP system. Even more, we can determine which compatibility level was chosen for this event, as such consumers know exactly which changes to expect when starting to consume those product events.
This simplistic example shows us that the documentation coexists with the actual schema. It is the responsibility of the owner to maintain the documentation. That is great, but we need to be able to share this information in a straightforward way for it to become really useful. You do not want to force interested users, e.g. business analysts, to have to scan raw Avro schema definitions every time they are looking at the capabilities of the system. We want an easily digestible format that provides a quick overview of all events and possibly even provides advanced search features.
A promising and simple tool to generate a more user-friendly format is: Avrodoc (plus). This tool can take multiple Avro schemas as input and generate interactive HTML output that provides an overview of all the existing events and their potential relations. It is then possible to select a specific event and see the documentation as provided in its schema. The advantage of the HTML output is that it can be hosted and made public for others to access and browse.
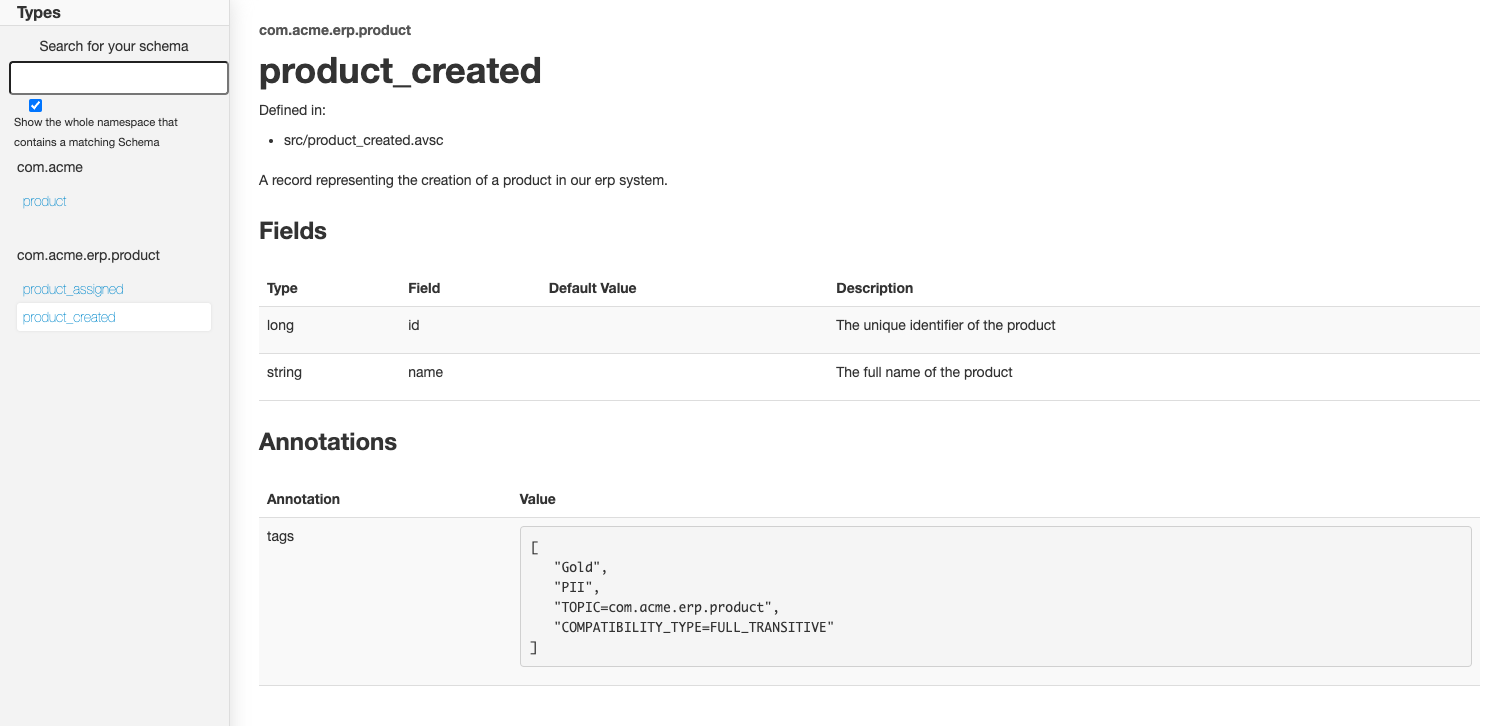
The screenshot above shows what the output might look like. There are possibilities to tweak the output to better fit your corporate identity. Another aspect shown is the search function on the top left. More than anything, having the ability to search through the events is what makes such documentation really useful. However, the search functionality is limited to the namespace and schema name.
What we definitely want as well, is the ability to search the internal structure of the events. For example, say I want to find all the events that transmit data about bank accounts. This might not be apparent from the event name, but could be mentioned in one of the fields or even in the documentation of the event. Who knows, this might be a feature in future releases of Avrodoc.
Look Ma, A Reference!
For recurring data blocks or data blocks that must follow a particular convention, e.g. enforced by an organizational standard, we strongly suggest extracting this as a separate “common” schema that other schemas can reference. This avoids duplication and inconsistencies. It can also help to better understand how certain events are related to one another.
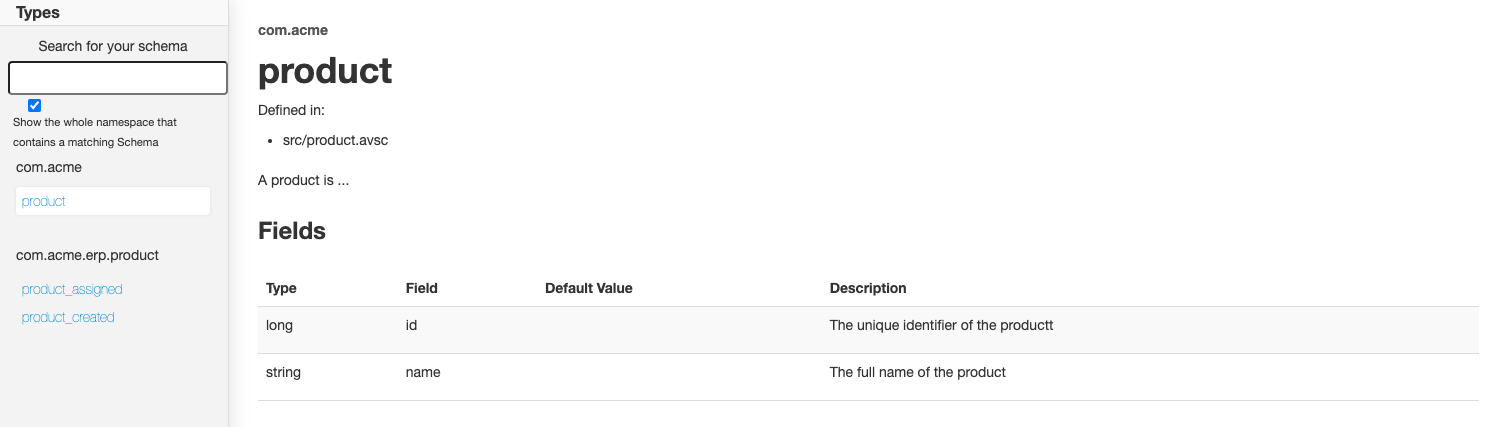
Let’s take our previous example of a “product creation” event. Instead of inlining all product-specific fields, we can extract this data into a separate schema and define it as a custom type that we can then reference in our “product creation” event or any other product-related event. The result looks like this:
product.avsc
{
"type": "record",
"name": "product",
"namespace": "com.acme",
"doc": "A product is ...",
"fields": [
{
"name": "id",
"type": "long",
"doc": "The unique identifier of the product"
},
{
"name": "name",
"type": "string",
"doc": "The full name of the product"
}
]
}product_created.avsc
{
"type": "record",
"name": "product_created",
"namespace": "com.acme.erp.product",
"doc": "A record representing the creation of a product in our erp system.",
"tags": [
"Gold", "PII",
"COMPATIBILITY_TYPE=FULL_TRANSITIVE"
],
"fields": [
{
"name": "product",
"type": "com.acme.product",
"doc": "The product that was created"
},
{
"name": "a_field",
"type": "string",
"doc": "Something that is specific about a product being created"
}
]
}product_assigned.avsc
{
"type": "record",
"name": "product_assigned",
"namespace": "com.acme.erp.product",
"doc": "A record representing the assignment of a product to a production pipeline.",
"tags": [
"Gold", "PII",
"COMPATIBILITY_TYPE=FULL_TRANSITIVE"
],
"fields": [
{
"name": "product",
"type": "com.acme.product",
"doc": "The product that was created"
},
{
"name": "another_field",
"type": "string",
"doc": "Something that is specific about a product being assigned"
}
]
}By extracting product-specific data into a separate schema we can reference it in different events. We are now certain that the structure of the product data and its documentation remains consistent across events and can focus our attention on the actual content of the business event.
The result of using references can also be reflected when using documentation generation tools like Avrodoc. The following images show that the HTML output now includes a separate product page that defines the common data fields for a product and two separate pages for the events associated with those products. The “product_created” and “product_assigned” pages now have an interactive link to the product details.
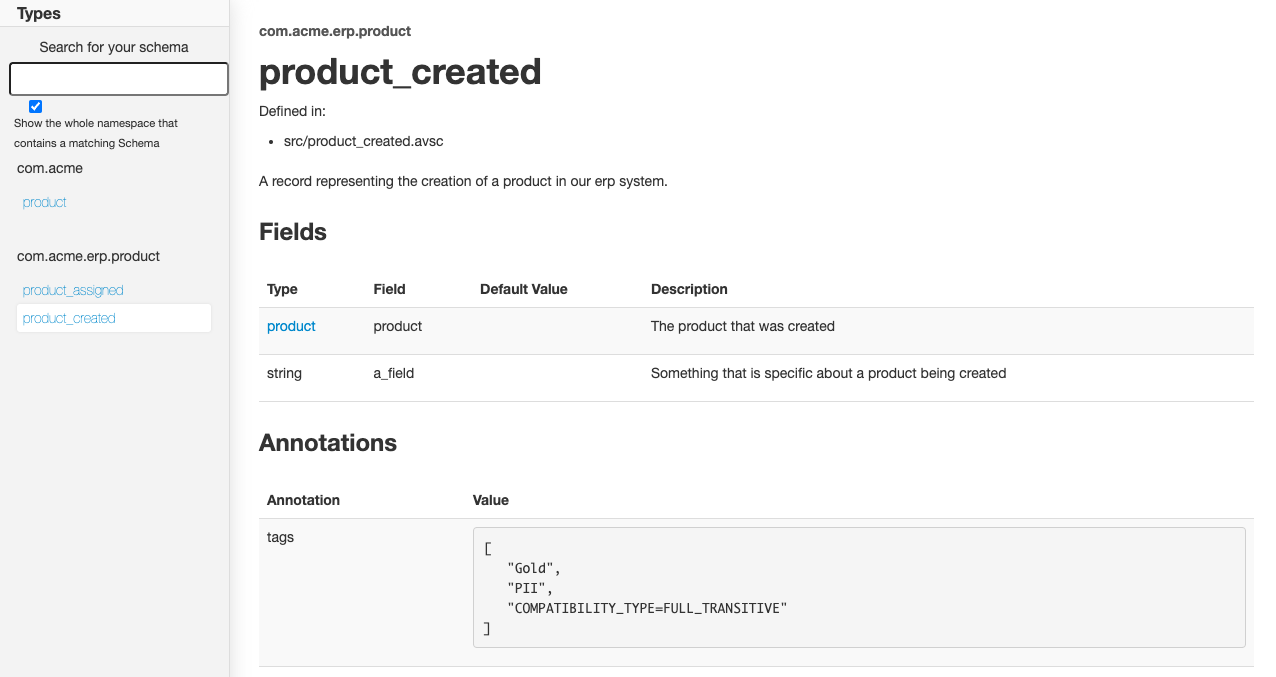
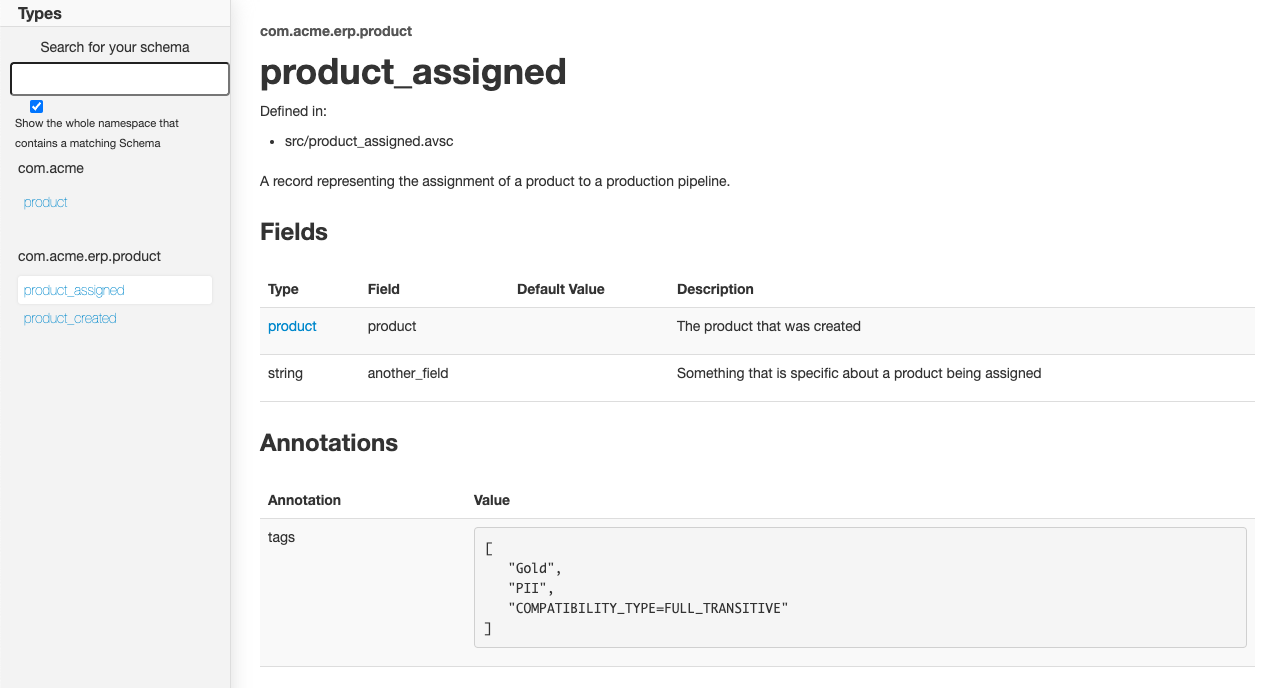
Do you want to be my meta?
If we’re talking about references to better organize your schemas, we might as well talk about standardizing certain parts of our events, such as their metadata. While metadata is not strictly speaking documentation and might be stretching the scope of this blog, I still found it important to mention how we at Cymo view metadata as it can certainly provide context to your events, help simplify certain parts of your EDA and even automate certain processes.
We know from experience that it is particularly difficult to get well-defined events. This requires a lot of coordination, discussion and agreement with different stakeholders about the payload of these events. Unfortunately, this is a process we must go through and that cannot be optimized as the content of events is highly dependent on the context of the customer or organization’s domain. However, one aspect that we can (and strongly recommend to) standardize, is what metadata is provided with each event and how this metadata is added to the event. This avoids repeated discussions about the basic structure of events and ensures alignment across your Event-Driven Architecture.
It is important to understand the difference between the metadata and the payload of the event. The payload is the actual content of the event. In other words, all the important information that is mandatory to understand the event. For example, a “product created” event has no meaning if the product that has been created is not part of the payload. Metadata, on the other hand, is additional information about the event that can provide context for certain consumers. Keep in mind that metadata must not affect the understanding of the payload of the event itself.
As such, we regard event metadata as purely technical in nature and we separate it completely from the actual payload. The provided metadata can vary greatly depending on the organizational needs and context. Here is an example of what metadata might be included:
{
(1) "event_id" : "c6066eda-06a7-4592-ba55-99569dfad1c4",
(2) "transaction_id" : "8bd94103-143b-4b0f-90cb-c083789a4fe7",
(3) "correlation_id" : "b24eae71-6dcd-4ae3-bd90-6392d88dd8d2",
(4) "publication_time" : "2023-11-28T09:05:00Z",
(5) "content_type" : "application/*+avro",
(6) "origin" : "https://acme.com/erp/product/create",
...
}Event id: a unique id that identifies this event instance
- Transaction id: the id of the transaction to which this event belongs
Useful when a transaction spans multiple events
- Correlation id: the reference to the event id of another event
E.g. when an event is part of a command/response pipeline
- Publication time: the timestamp indication when the message was effectively published by the producer
This might differ from the broker timestamps due to numerous factors, such as network availability
- Content type: the format used for the payload
Useful when using multiple formats within the same landscape, e.g. Avro and Protobuf
Origin/Source: the source system that produced the event or the original interface that triggered the event
As you can see, the list can grow depending on your specific requirements. It could even include more specific information about a certain technology used within your organization. Consider a monitoring framework such as open telemetry.
Now that we understand what event metadata can be, how do we add it to our events? There are two options when adding metadata to events. We can either add the metadata as headers when publishing the event or we can add the metadata as part of the event itself.
Adding the metadata as headers is fairly straightforward. However, we have to keep in mind that headers do not enforce a certain structure or have any implicit validation. As such, it is perfectly possible to send incorrectly structured metadata. This can be overcome by adding the metadata to the event and using schemas to enforce structure.
Careful though, and remember that the metadata must be strictly separated from the payload. Therefore, it is important to enforce this even when adding the metadata to the event itself. Below is an example of what our “product created” event might look like if we add the metadata to the event itself:
product_created.avsc
{
"type": "record",
"name": "product_created",
"namespace": "com.acme.erp.product",
"doc": "A record representing the creation of a product in our erp system.",
"tags": [
"Gold",
"PII",
"COMPATIBILITY_TYPE=FULL_TRANSITIVE"
],
"fields": [
{
"name": "meta",
"type": {
"type": "record",
"name": "meta_data",
"fields": [
{
"name": "event_id",
"type": "string",
"doc": "the technical event id"
}
]
}
},
{
"name": "payload",
"type": {
"type": "record",
"name": "payload_data",
"fields": [
{
"name": "product",
"type": "com.acme.product",
"doc": "The product that was created"
},
{
"name": "a_field",
"type": "string",
"doc": "Something that is specific about a product being created"
}
]
}
}
]
}Those that made it this far and didn’t skip the previous section will note that this is a good opportunity to use schema references to avoid duplication of those metadata blocks and greatly reduce the size of your output documentation.
A good starting point when defining your metadata is to use standards that have emerged as a result of the growing popularity of EDA. A good example of such a standard to structure your events is Cloud Events. Of course, do not hesitate to contact us if you have any further questions on this topic. We will gladly help you get on the right track.
Is there more? AsyncAPI, you say?
Avro or other similar frameworks focus on the event structure and provide a good foundation to understand the events within an Event-Driven Architecture. But what about the system itself? What happens when our system contains a hybrid mix between different async and sync protocols? How do your users know that a published interface is available through REST, MQTT, Kafka, Server Sent Events or some other protocol? In essence, we also want to document which interfaces are available, how they behave and what purpose they serve.
An emerging specification for asynchronous interfaces is AsyncAPI. The AsyncAPI specification was created for asynchronous interfaces based on how OpenAPI can be used to describe synchronous interfaces. This facilitates the adoption of AsyncAPI as it has a similar structure to the OpenAPI specification with counterparts for asynchronous components. The AsyncAPI specification is intended to be protocol agnostic, but works with the concept of bindings to support providing protocol-specific information. For example, when using Kafka, you can use the kafka binding to provide the url of your schema registry or provide information about the retention of your topics.
Working further on our product example, what would a basic AsyncAPI specification document look like:
product.yaml
asyncapi: 2.6.0
id: "urn:acme:erp:product-events"
info:
title: Product events
version: "1.0.0"
description: |-
# ACME ERP Product events, produced on Kafka
ERP Product events are produced whenever something is changed on the product, basic data updates but also state changes, actions for a product, ...
This document describes these events in detail. The structure of the payload is defined by avro schemas which are also deployed in the Confluent schema registry
license:
name: Apache 2.0
url: https://www.apache.org/licenses/LICENSE-2.0
tags:
- name: erp
- name: a-company-tag
externalDocs:
description: This wiki describes how EDA is implemented at your Company
url: https://some-url-to-your-wiki/
channels:
acme.product:
publish:
message:
oneOf:
- schemaFormat: "application/vnd.apache.avro;version=1.9.0"
payload:
$ref: "./product_created.avsc"
- schemaFormat: "application/vnd.apache.avro;version=1.9.0"
payload:
$ref: "./product_assigned.avsc"Even though this is a simple example, we can already see models being reused, like our Avro schemas. In this blog, I will not go into all the details of AsyncAPI and its capabilities. A good way to get started with AsyncAPI is their documentation.
The main point I want to emphasize is that AsyncAPI is multi-purpose. On the one hand, the specification is machine-readable and can be used for all kinds of automation to set up your architecture. You could do real-time validation of your messages, automated testing and code generation, all based on the same specification. On the other hand, the specification can also be used to generate documentation that is human-readable and digestible by different kinds of stakeholders. The very simple example above can produce the following output that is ready to be published and shared:
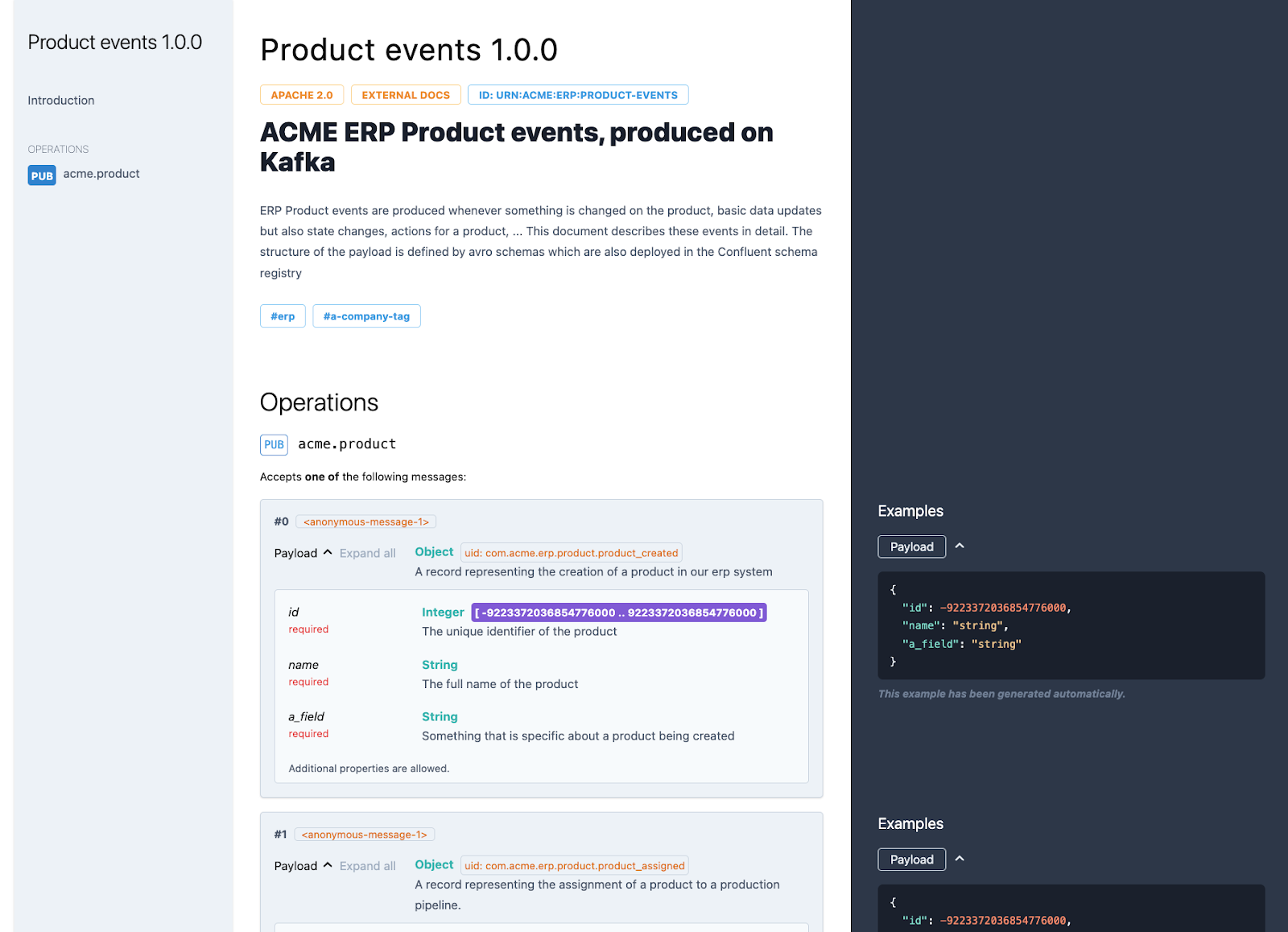
As you can see, this documentation is more extensive than the documentation we generated purely from the Avro schemas in the previous section. It is possible to add rich text documentation, references to other external documents, add certain tags, provide examples …
Avrodoc focuses more on the documentation of contracts (i.e., events) and its output is aimed at technical readers. The goal of AsyncAPI is more concerned with the documentation of the event streams that live in your architectural landscape. AsyncAPI documentation can be understood by a broader audience and serves to provide a bigger picture of your architecture while still providing detailed information about the structure of the existing events in your system.
HTML output is not the only output AsyncAPI can generate. There are other generators, such as the React generator, that can produce components that can be incorporated by different frameworks and included in an even broader context. Think of data catalogs that provide information about both your asynchronous and synchronous interfaces or digital marketplaces that allow customers to subscribe to your data products based on your AsyncAPI specification documents.
Perception failed: Acro reference schemas
While using AsyncAPI in combination with Avro schema definitions (AVSC), we noticed that there is no support for reference schemas. As mentioned in the previous section, we advocate the use of reference schemas to avoid duplication. Although it is possible to reference Avro schemas within an AsyncAPI specification document, the AsyncAPI Avro parser lacks the ability to process Avro schemas that contain references to other Avro schemas themselves.
In this case, the parser generates an error and it is not possible to generate any documentation. A solution we have implemented in the past is an extra step in the CI/CD pipeline that parses the Avro schemas and when it encounters a schema reference, it inlines the reference schema directly into the original schema. The resulting schemas can then be used in your AsyncAPI.
A simpler approach would be the use of Avro IDL, a higher-level language to define Avro schemas. It is more concise and human-friendly to read than the original AVSC definitions. However, using AVDL does require learning a new syntax and needs an extra step to generate the AVSC definition for further processing. As an added bonus, though, this process inlines all references that occur. For instance, we could have the following AVDL for our product example:
product_protocol.avdl
@namespace("com.acme.erp.product")
protocol ProductProtocol {
import schema "product.avsc"; // can reference avsc, avdl or avpr
/** A record representing the creation of a product in our erp system */
@tags(["Gold", "PII", "COMPATIBILITY_TYPE=FULL_TRANSITIVE"])
record product_created {
com.acme.product product;
/** Something that is specific about a product being created */
string a_field;
}
/** A record representing the assignment of a product to a production pipeline. */
@tags(["Gold", "PII", "COMPATIBILITY_TYPE=FULL_TRANSITIVE"])
record product_assigned {
com.acme.product product;
/** Something that is specific about a product being assigned */
string another_field;
}
}This is definitely easier to work with and less lengthy than using plain JSON to describe our contracts. To be able to use this with AsyncAPI or other tools like code generators, we must first convert the AVDL to plain AVSC definitions. This can be done with the Avro Idl to schemata functionality. Using “avro-tools”, it would look like this:
// usage: avro-tools idl2schemata [input] [output]
java -jar avro-tools.jar idl2schemata src/product_created.avdl buildThe output of this operation matches the Avro schemas we defined in the previous section. Below, you can find the output that was generated for the “product created” event. The “product assigned” schema was also produced, but is left out here as this blog has already grown largely beyond my original intent. Looking closely at the output, we can also see that the reference to the product schema (product.avsc) has effectively been inlined and therefore solved our issue with AsyncAPI.
build/product_created.avdl
{
"type" : "record",
"name" : "product_created",
"namespace" : "com.acme.erp.product",
"doc" : "A record representing the creation of a product in our erp system",
"fields" : [ {
"name" : "product",
"type" : {
"type" : "record",
"name" : "product",
"namespace" : "com.acme",
"doc" : "A product is ...",
"fields" : [ {
"name" : "id",
"type" : "long",
"doc" : "The unique identifier of the product"
}, {
"name" : "name",
"type" : "string",
"doc" : "The full name of the product"
} ]
}
}, {
"name" : "a_field",
"type" : "string",
"doc" : "Something that is specific about a product being created"
} ],
"tags" : [ "Gold", "PII", "COMPATIBILITY_TYPE=FULL_TRANSITIVE" ]
}Conclusion: Do it, but correctly
It should be clear by now that we strongly advocate documenting your events correctly. The most important part of your documentation should be the fact that it is dynamic in nature. That is, the documentation should actively change with the changes of the system. As such, documentation becomes the link between the meaning of your system and its implementation.
Depending on your context, it may be better to stick to more straightforward documentation that focuses on your contracts/events such as Avrodoc. However, once the system starts to get larger and there are different kinds of stakeholders involved, it may be time to look at more comprehensive documentation like AsyncAPI. It clarifies the interconnection of your events, the event streams that live in your architecture, and it can provide additional information digestible for non-technical readers.
If you want to know which approach would best fit your context, want to know more about documenting your Event-Driven Architecture, and/or just need guidance with your EDA adventure, do not hesitate to contact us.
Contact us!
Written byChristophe Vandenberghe
Read more
Integrating Salesforce in an Event-Driven Architecture

Enhanced Cybersecurity through Event-Driven Architectures
In this blog, we'll take a closer look at the benefits of using an Event-Driven Architecture, which challenges you'll need to consider, and which strategies and tools can help you overcome these challenges.